|
Technical Overview
|
  |
|
Technical Overview
|
|
Heurist is a system for storing descriptive information about, and connections between, a heterogeneous set of entities, and delivering this information on-the-fly in a variety of programmable formats including XML feeds, html, RDF, data exchange formats, interactive maps and timelines. A relationship browser framework allows multiple linked views (record view, linked list, map, timeline) to be navigated together.
The information stored for entities can include a dynamically defined range of textual attributes and pointer variables, geographic and temporal information, extended rich text, internal annotations and digital representations. Heurist also manages differential access based on user and workgroup profiles, personal bookmarks, personal, public and workgroup notes, tagging and keywording, with social functions such as tag-following, collaborative rich text and blogging.
Heurist is implemented as a server-based MySQL/PHP/Javascript application. The HAPI (Heurist API, fully developed), GOI (Geographic Object Interface, fully developed) and TOI (Temporal Object Interface, in planning stage) programming APIs allow development of applications that use Heurist without needing direct access to the underlying data structures.
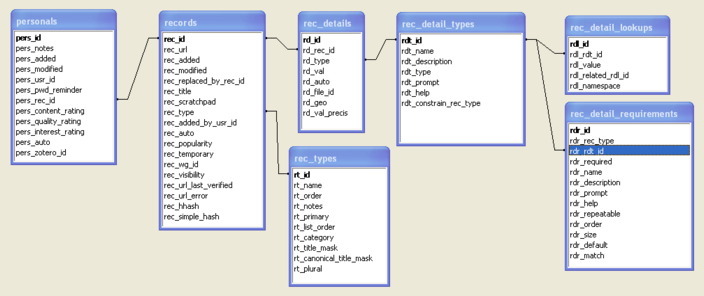
Heurist implements a number of original underlying data structuring methodologies. Entities are represented by a record in a primary database table. Attributes of entities are represented by records in an instance table linked by a foreign key to the primary table. Record types in the primary table and the metadata elements used to store attributes are defined in a series of lookup tables which define the use of both unique and shared attributes in different record types – definitions are thus soft-coded and can be modified without rebuilding the database.
User bookmarks are represented by records in a bookmarks table linked by a foreign key to the primary table. Search parameters can be stored in a saved search table. Rich text segments are stored as binary objects which can be assembled into documents on the fly. Digital objects are stored as files on disk indexed by the database. Bibliographic relationships, as well as other relationships between primary records, are stored through internal pointers implemented as attributes, and internal pointers also allow embedding of other resource records within rich text fields.
All primary, bookmark, saved search and rich text segment records store the identity of their creator and workgroup ownership as foreign keys to the user and workgroup tables, allowing application of read and modification policies on the fly. Rich text segments in addition store specific read/write permissions down to individual user granularity. Users belong to one or more workgroups defined through workgroup lookup tables and also have the ability to define their own colleague groups.
Multiple Heurist instances can reference the record type and metadata definitions in the primary instance, while providing customised views of these definitions for a particular application or user group. Heurist stores creation and modification date of all main record types. The database stores a granular audit trail of all database changes using database triggers, allowing selective rollback of the data, although rollback routines have not yet been implemented.
Since the database structure of Heurist is relatively simple, the data management and permissions-controlled access methodologies are implemented through a complex backend implemented in MySQL and PHP. A Javascript API is provided for use by all custom applications which are built on a Heurist backend database. A general-purpose interface provides generic methods of defining, importing, editing, managing, searching and viewing data in Heurist.
Import methodologies include bookmarking of web pages, harvesting of hyperlinks from web pages, text file parsing, XML, GML and KML import including geographic objects and import of bibliographic exchange formats including heuristic record identification, disaggregation of hierarchical relations and creation of record relationships. Output methodologies include a method of generating comprehensive XML data dumps with controllable nesting of related records, XSLT processing for the generation of formatted output, RSS feeds and web services to specific applications.
Specific research has been carried out leading to a methodology for representing networks of relationships between entities, modelled using Heurist relationships and visualised through a relationship browser. Relationships are directional, record a relationship type based on an ontology, can be geographically and temporally located, and inherit all the other functionality of Heurist records (attributes, ownership, notes and annotation, tagging, searchability etc.). The relationship browser uses multiple linked views to visualise a record and its related records, and navigate all the views together. The relationship browser provides a record view (with attributes, rich text and embedded annotations), a linked list (with summary data including thumbnails and grouping by relationships), an interactive map (with spatial search and filtering, multiple map layers, symbols, connecting lines, labelling and rollover/popup information) and an interactive timeline (with time filtering, symbols, spans, labelling and rollovers/popups).